



Introduction
Window functions are special types of functions in SQL that allow performance calculations in a set of rows within a query, known as a window. This is comparable to calculations done using aggregate functions such as SUM, AVG, MIN, MAX and COUNT. However window functions do not cause the rows to the grouped into a single output row like aggregate functions, rather they retain their separate identities. This allows you to perform calculations that consider the context of neighbouring rows, which can be very powerful for data analysis.
Why Window Functions is special
Window functions go beyond simple aggregations. They provide powerful capabilities such as:
Ranking rows: Determine the position of a row within a group based on a specific order.
Cumulative calculations: Track running totals, moving averages, or percentile rank as you move through the dataset.
Comparing values: Analyze current data points about past or future values within the window.
Identifying gaps or outliers: Highlight missing or unusual data points based on their neighbours.
Efficiency and expressiveness: Often, achieving similar results with traditional methods would require complex joins or subqueries. Window functions offer a more concise and efficient way to express these kinds of complex calculations, streamlining your coding and increasing readability.
Flexibility and control: You have tremendous control over how window functions work. You can define the size and order of the window, and even partition data into groups for separate analysis within each group. This fine-grained control allows you to tailor your analysis to your specific needs.
For this article, I will use PostgreSQL16, Dbeaver as my database manager. The database is the Northwind database: A very popular database used for demos that represents a customer and sales data from a fictitious company.
Basic Structure of a Window Function
SELECT
column1,
column2,
window_function(column_name) OVER (
[PARTITION BY partition_column1, partition_column2, ...]
ORDER BY order_column [ASC | DESC]
ROWS/RANGE BETWEEN start_point AND end_point
) AS alias_name
FROM
table_name;
SELECT: Specifies the columns to be selected from the table.
window_function: The specific window function being used, such as
SUM,AVG,ROW_NUMBER,RANK, etc.OVER: Indicates the beginning of the window function clause.
PARTITION BY: (Optional) Divides the result set into partitions to which the window function is applied separately. It is used to group rows into separate partitions before applying the function. If not specified, the function is applied to the entire result set.
ORDER BY: (Optional) Specifies the order of rows within each partition. It defines the logical ordering of rows in each partition, which affects the window frame. If not specified, the default order is ascending order.
ROWS/RANGE BETWEEN: (Optional) Specifies the window frame or the range of rows within each partition to which the function is applied. It defines the subset of rows within the partition to be included in the calculation.
start_point and end_point: (Optional) Define the starting and ending points of the window frame. It could be
UNBOUNDED PRECEDING,CURRENT ROW,UNBOUNDED FOLLOWING, or a specific number of rows or a range.
For example
SELECT PRODUCTNAME,
PRICE,
AVG(PRICE) OVER(ORDER BY PRODUCTNAME)AS AVERAGE_PRICE
FROM PRODUCTS;
SELECT PRODUCTNAME, PRICE: This part of the query selects two columns from thePRODUCTStable -PRODUCTNAMEandPRICE.AVG(PRICE) OVER(ORDER BY PRODUCTNAME) AS AVERAGE_PRICE: This part calculates the average price of products.AVG(PRICE): It calculates the average of thePRICEcolumn.OVER(ORDER BY PRODUCTNAME): This is where the window function is applied. It specifies that the average calculation should be done over a window of rows ordered by thePRODUCTNAMEcolumn. So, for each row in the result set, the average price will be computed based on the prices of all preceding rows ordered byPRODUCTNAME.AS AVERAGE_PRICE: This part assigns an alias nameAVERAGE_PRICEto the calculated average, making it easier to refer to in the output.
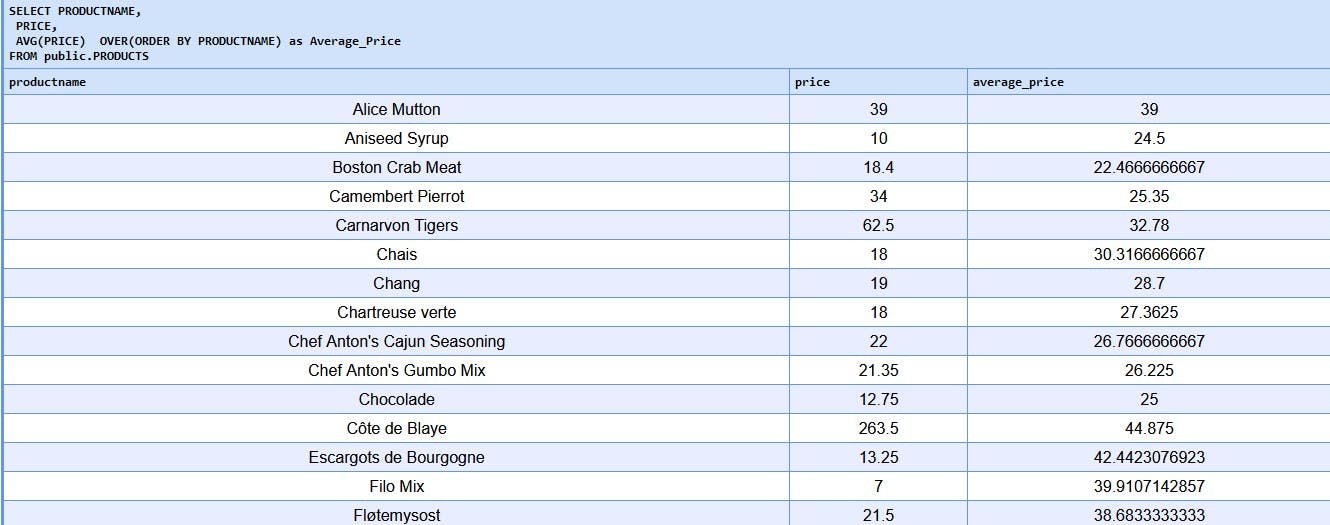
The query returns three columns: PRODUCTNAME, PRICE, and AVERAGE_PRICE. For each row in the result set, PRODUCTNAME and PRICE will be directly fetched from the PRODUCTS table, while AVERAGE_PRICE will display the average price of all products up to that row, ordered by product name.
Common Types of in-built Window Functions
There are three main types of in-built window functions. They are:
Ranking Functions
Aggregate Functions
Value Functions
Ranking Functions
These assign a rank or position to each row within a group. They are row_number, rank, dense_rank, and ntile functions.
ROW_NUMBER(): This assigns a unique sequential number to each row.
select
row_number() over(partition by categoryid
order by
productname) as row_number,
productname,
price
from
public.products;
This gives a unique number to each row starting from one having being grouped by the categoryid and ordered in ascending order by the productname.

RANK(): This assigns a rank with possible gaps for ties. For example if there are values in a row which are in the same position. They would be given the same position hence the ties. The next position will have a gap indicating the tie before it.
select
productname, price,
rank() over (order by price)
from products;
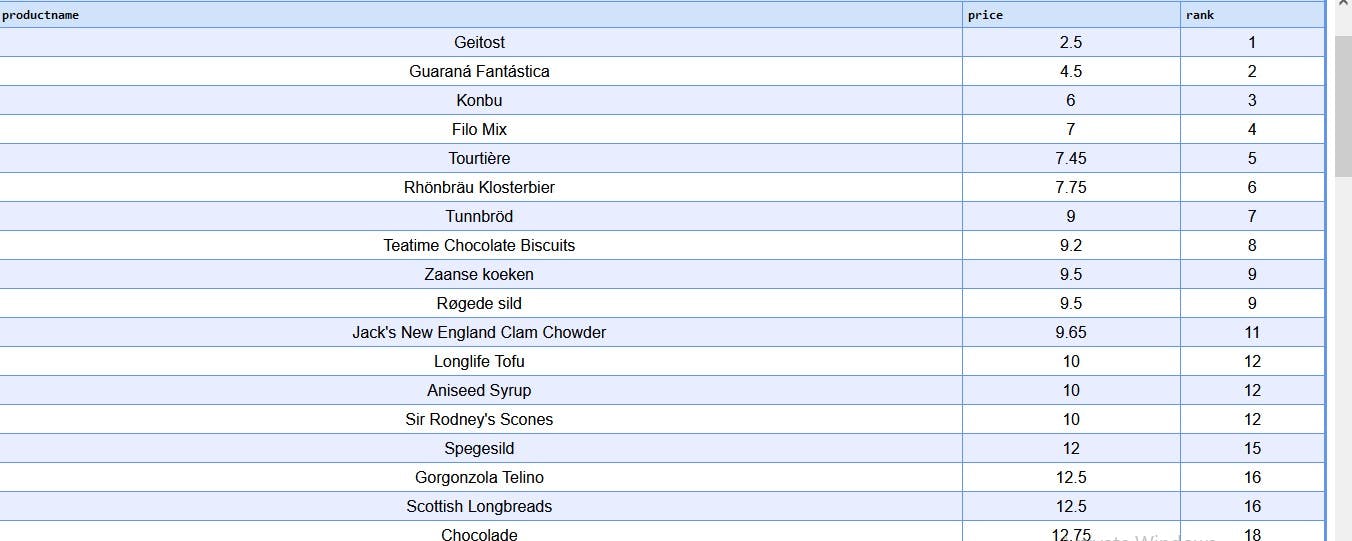
You can see in the rank column in the 12th rank which has 3 ties, the next position is 15.
DENSE_RANK(): This assigns a rank without gaps for ties.
select
productname,
price,categoryid ,
dense_rank() over (partition by categoryid
order by price)
from
products;
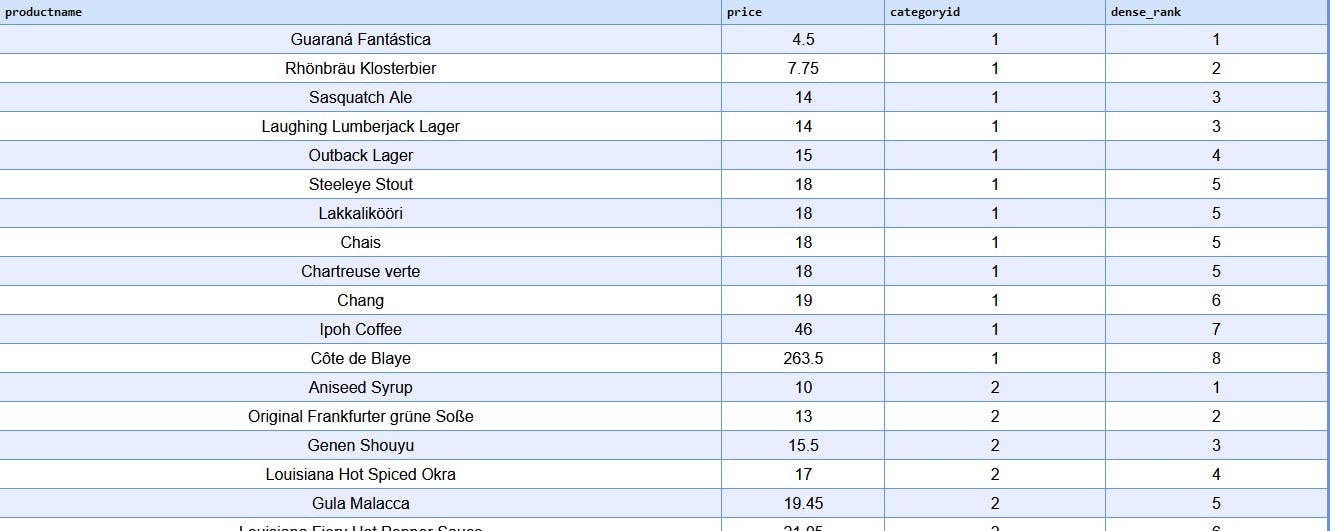
Here there are no gaps in the ties. After the 5th position, the next position is 6. This is what differentiates it from the RANK function.
NTILE(): This divides an ordered dataset into a specified number of approximately equal-sized groups or “tiles”. It assigns a group number to each row based on the specified number of tiles.
select
productname,
price,
categoryid,
ntile(4) over (partition by categoryid
order by
price) as price_group
from
products;

The NTILE(4) function divides the dataset into three groups. Each row is assigned a price_group based on its position within the ordered dataset. The rows with the lowest price are assigned to group 1, the third highest price group 2, second highest price to group 3, and the highest price group 4. If the number of rows is not evenly divisible by the number of groups, some groups may have one more row than others, but the difference in the number of rows between groups will be at most 1.
Aggregate Functions
They perform calculations across a window. They include sum, avg, min, max and count functions.
SUM(): This calculates the sum of values within a window.
AVG(): This calculates the average of values within a window.
MIN(): This displays the minimum value within a window.
MAX(): This displays the maximum value within a window.
COUNT(): This counts the number of rows within a window.
select
productname,
price,
categoryid,
sum(price) over (partition by categoryid
order by
price) as total_category_price,
avg(price) over (partition by categoryid
order by
price) as average_category_price,
count(price) over (partition by categoryid
order by
price) as count_category_price,
max(price) over (partition by categoryid
order by
price) as max_category_price,
min(price) over (partition by categoryid
order by
price) as min_category_price
from
products;

Value Functions
They access values from other rows within the window. They include lag, lead, first_value, last_value functions.
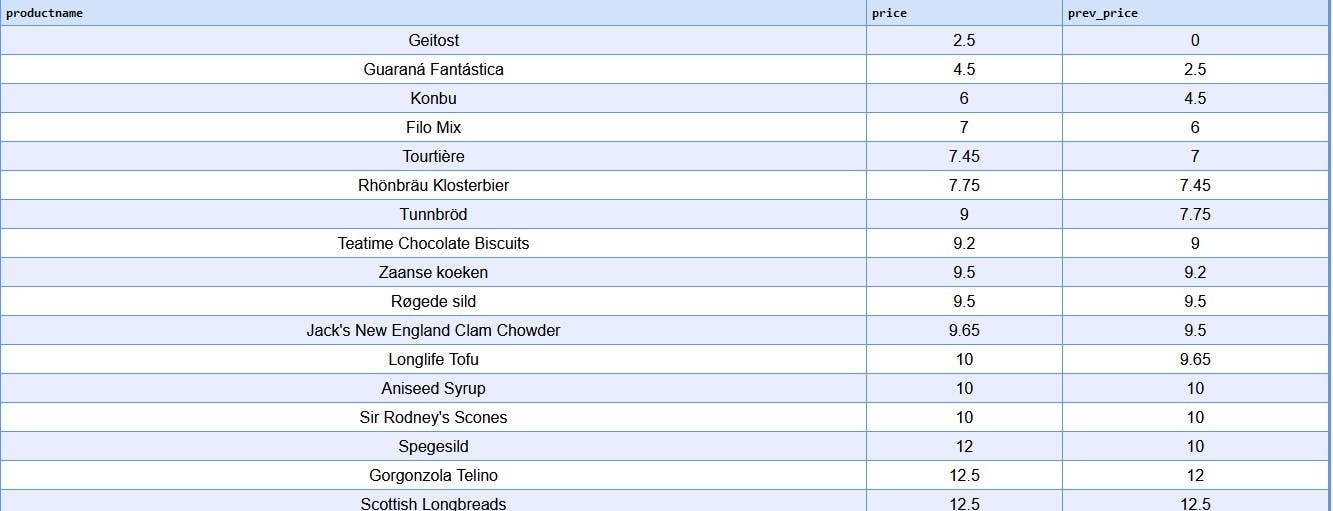
LAG(): This returns the value from a previous row.
The basic syntax of this Windows function
LAG(column_name, offset, default_value) OVER (ORDER BY order_expression)
column_name: The column whose value you want to retrieve from the previous row.offset: Optional. Specifies the number of rows back from the current row to retrieve the value. Default is 1.default_value: Optional. Specifies a default value to return if the offset row does not exist. Default is NULL.
select productname, price,
lag(price,1,0)over(order by price)as prev_price
from
products;
LEAD(): It returns the value from a subsequent row. The basic structure is similar to the LAG function.
select productname, price,
lead (price,1,0)over(order by price)as next_price
FROM
products;

You could also use it to determine the difference in values.
select productname,price, price-
lag(price,1,0)over(order by price)as diffence_price
FROM
products;

FIRST_VALUE(): It returns the first value in an ordered partition.
The basic syntax of this window function is
FIRST_VALUE(column) OVER (PARTITION BY column ORDER BY column)
column: The column from which to retrieve the value.
partition by: Optional clause to partition the dataset into groups based on one or more columns.
order by: Defines the order of rows within each partition.
select
productname, price,categoryid ,
first_value(price)over(partition by categoryid order by price)
from products;
In this example, you can see that the first value of each category id was displayed in the first_value column.
LAST_VALUE(): This returns the last value of the window function.
select
productname, price,categoryid ,
last_value(price)over(partition by categoryid order by price)
from products;

Conclusion
Window functions in SQL provide a robust and flexible way to perform data analysis on a set of rows, known as a window, within a query. They offer more than simple aggregations, enabling efficient and expressive calculation methods, and allowing for greater control over how these calculations are performed. With a variety of in-built functions like ranking, aggregate, and value functions, they provide the capability to perform tasks such as ranking rows, cumulative calculations, comparing values, and identifying gaps or outliers. By understanding and implementing these functions, you can enhance your data analysis and manipulation capabilities in SQL.